A legtöbb dokumentumfeldolgozó rendszer egy ponton ugyanolyan tüneteket produkál: az OCR motor magas pontossági értéket jelez, a validációs sor mégis tele van. Napi rutin lesz a kézi javítás, és az automatizáció ígérete valahol elvész a folyamat közben. Nem feltétlenül a motor a hibás. A probléma mélyebb: karaktert felismerni és tartalmat érteni két különböző dolog. A GenAI-alapú dokumentumfeldolgozás éppen ezen a ponton lép be: a rendszer nem csak karaktereket ismer fel, hanem a tartalom jelentését és összefüggéseit is képes értelmezni.
Miért kritikus a képminőség az OCR előtt?
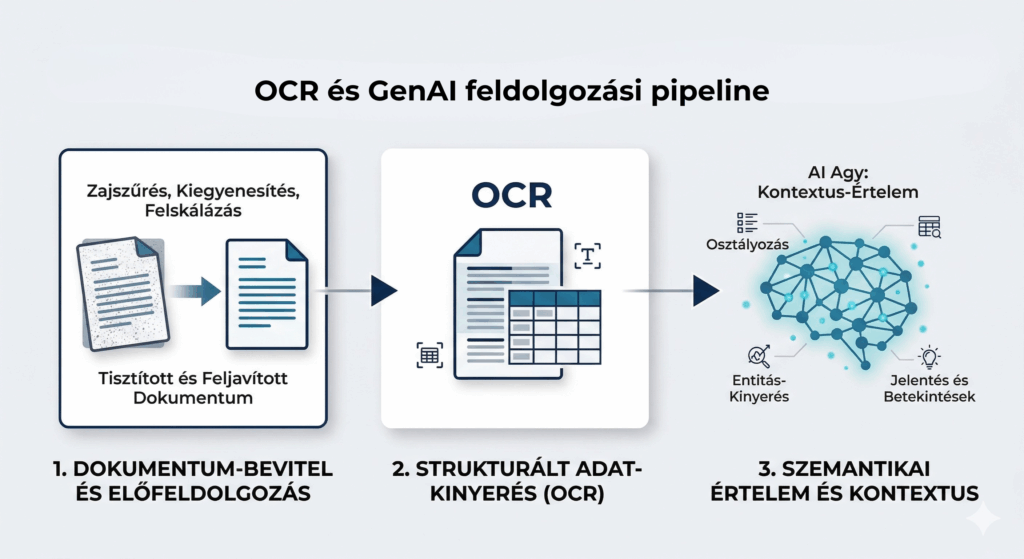
Az OCR teljesítménye nagyban függ a bemeneti anyag minőségétől, és az éles környezetekben ez ritkán ideális. Irodai szkenner, telefonfotó, faxból mentett PDF, évtizedes archívumból digitalizált irat: mind más minőségű bemenetet jelent.
Éppen ezért a feldolgozási pipeline első lépése nem a felismerés, hanem az előkészítés. Három területen érdemes beavatkozni:
Denoising: a szkennelési zajok (pöttyök, kosz, árnyékok) eltávolítása. Ezek aprónak tűnnek, de az OCR motorok érzékenyek rájuk, és hibás karakterfelismeréshez vezetnek.
Deskewing: a ferdén beszkennelt lapok szoftveres kiegyenesítése. Néhány fokos eltérés elegendő ahhoz, hogy a sor- és oszloptörések eltolódjanak, ami tábláknál különösen kritikus.
Upscaling: a felbontás növelése olyan szintre, ahol a karakterek részletei jól elkülönülnek (tipikusan 200–400 DPI tartományban). Fontos, hogy az upscaling önmagában nem pótolja a hiányzó információt, de javíthatja az OCR olvashatóságát. Az apróbetűs részek, táblázatcellák és fejlécek megfelelő karakterméret és kontraszt mellett válnak megbízhatóan olvashatóvá, ami jellemzően ebben a felbontási tartományban teljesül. Ez elsősorban az OCR rétegre igaz: a natív vision képességű LLM modellek valamivel toleránsabbak az alacsonyabb felbontásra, de a jó előfeldolgozás az egész pipeline teljesítményét javítja.
Ez a három lépés az alapréteg. Nélküle a legjobb motor sem tud jól teljesíteni, de önmagában még nem oldja meg a valódi problémát.
Miben nem elég önmagában az OCR?
Az OCR elsősorban egy karakterfelismerő technológia. Pontosan csinálja, amire tervezték: a képen lévő karaktereket szöveggé alakítja. A korlátai is ebből következnek.
Egy hagyományos OCR-alapú feldolgozónak nincs fogalma arról, hogy az „Esedékesség”, a „Fizetési határidő” és a „Due Date” ugyanazt jelenti. Ha egy partner megváltoztatja a számla fejlécét, az előre beállított sablonszabály megáll, és kézi beavatkozás szükséges. A táblázatból a cellatartalmat kiszedi, de azt nem tudja, hogy az adott érték melyik oszlopfejléchez tartozik, és melyik sorhoz kapcsolódik.
A probléma strukturális: a hagyományos OCR elsősorban pozíciót és karaktert lát, és csak korlátozott mértékben kezeli a kontextust.
Hogyan értelmezi a tartalmat a multimodális GenAI?
A modern multimodális nagy nyelvi modellek (LLM) itt lépnek be, és nem az OCR-t helyettesítik, hanem a folyamat egy külön rétegét képezik.
Egyszerre lát és olvas. A multimodális modell a vizuális elrendezést és a szöveges tartalmat egyszerre dolgozza fel. Képes figyelembe venni a táblázatstruktúrát, a logó pozícióját, valamint a fejléc–lábléc viszonyt, és ezeket az összefüggéseket az értelmezés során is hasznosítja.
Szemantikai értelmezés. A modell nem koordinátát keres, hanem jelentést. Felismeri, hogy egy mező melyik fogalomnak felel meg, akkor is, ha más szóval írták, más pozícióban szerepel, vagy egy folyószöveg részeként jelenik meg, nem strukturált mezőként.
Táblázatok, diagramok, képek. Az OCR a táblázatból szöveget szed ki. A GenAI az összefüggést is képes értelmezni: nagy valószínűséggel helyesen társítja, hogy melyik ár melyik tételhez tartozik, illetve melyik dátum milyen jelentésű, bár komplex táblák esetén ez továbbra sem minden esetben determinisztikus. Ez részben igaz diagramokra és egyéb vizuális elemekre is, amelyeket a hagyományos OCR nem tud értelmezni, bár ezek megbízható feldolgozása jelenleg erősen use-case függő.
Tartalom értelmezése, nem csak olvasása. A nagyobb kontextusablaknak köszönhetően a modell egy többoldalas dokumentumot egészként kezel, nem oldalanként dolgozza fel. Így az első oldalon szereplő fejléc összefüggésbe hozható a harmadik oldal tételeivel. A DMS-ekbe kerülő dokumentumok nagy többségére (számlák, szállítólevelek, szerződések tipikus változatai) ez teljes mértékben igaz, bár természetesen akadnak kivételek: egy több száz oldalas keretszerződés vagy összetett műszaki tanulmány más megközelítést igényelhet.
OCR és GenAI: hogyan működnek együtt a dokumentumfeldolgozásban?
Az OCR és a GenAI nem versenytársak. A struktúrafelismerés (táblázatok, bekezdések, vizuális blokkok azonosítása) jellemzően az OCR-re épülő layout-elemző eszközök erőssége marad, és ezt érdemes is megtartani. A szemantikai értelmezés, az adatnormalizálás (különböző dátumformátumok egységesítése, összegek ellenőrzése) és a logikai validáció a GenAI réteg feladata.
Fontos megjegyezni: ez egy bevált hibrid architektúra, de nem az egyetlen lehetséges megközelítés. Vannak tisztán multimodális megoldások is, amelyek az OCR lépést részben vagy teljesen kiváltják, ugyanakkor ezek pontossága, költsége és auditálhatósága erősen függ a konkrét use case-től. A megfelelő architektúra a feldolgozandó dokumentumok típusától és a meglévő infrastruktúrától függ.
A validációs rétegnél a különbség a leginkább kézzel fogható. A rendszer nem egyszerű OCR-százalékot ad vissza, hanem logikai és szemantikai ellenőrzést is végez, mielőtt „zöld jelzést” ad. Ez azt jelenti, hogy a validátornak nem kell minden mezőt megnéznie, csak azokat, ahol a rendszer bizonytalanságot, inkonzisztenciát vagy szabálysértést jelez.
Hol érdemes elkezdeni gondolkodni
A kérdés nem az, hogy az OCR jó-e vagy rossz. A legtöbb esetben a karakterfelismerés rendben van. A valódi szűk keresztmetszet az, hogy a folyamat hol veszít kontextust, és azt ki lehet-e váltani anélkül, hogy a meglévő rendszert ki kellene cserélni.
Ha inkább az érdekel, hogyan illeszthető be egy ilyen feldolgozási réteg a meglévő DMS-folyamatba anélkül, hogy bármit ki kellene cserélni, erről ebben a cikkben írunk részletesebben.
A technológia erre ma már adott, a kérdés az architektúra.
Ha kérdésed van arról, hogyan illeszthető be egy ilyen feldolgozási réteg a ti folyamatotokba: genai@nitrowise.com