Graics Vince, korábbi tesztelési vezetőnk nemrégiben tartott nálunk egy előadást arról, hogy hogy érdemes tesztelés során az AI jelenlegi lehetőségeit kiaknázni. Vince az utóbbi években technical lead és staff engineer pozíciókban dolgozott nemzetközi projekteken scale-upoknál. A munkája mellett is igyekszik elmélyülni a szakmájában, a WebdriverIO open-source projekt contributora. Az alábbi cikkben Vince összefoglalta előadása tartalmát.
Amikor az AI és a tesztelés kapcsolata szóba kerül, a téma legtöbbször a runtime-nál (futásidőnél) kezdődik, és ott is ér véget. A Copilot teszteket ír. Egy LLM gombokat nyomogat. Egy modell ellenőrzéseket (assertion-öket) generál.
Ez azonban csak egyetlen fázis. Van még kettő, amivel az utóbbi időben kísérleteztem, és pont ezeknél válik igazán izgalmassá a dolog.
A múlt héten tartottam erről egy előadást volt munkahelyemen, a Nitrowise-ban. 80 perc, három élő demó, egy haldokló laptop. Íme az írott verzió.
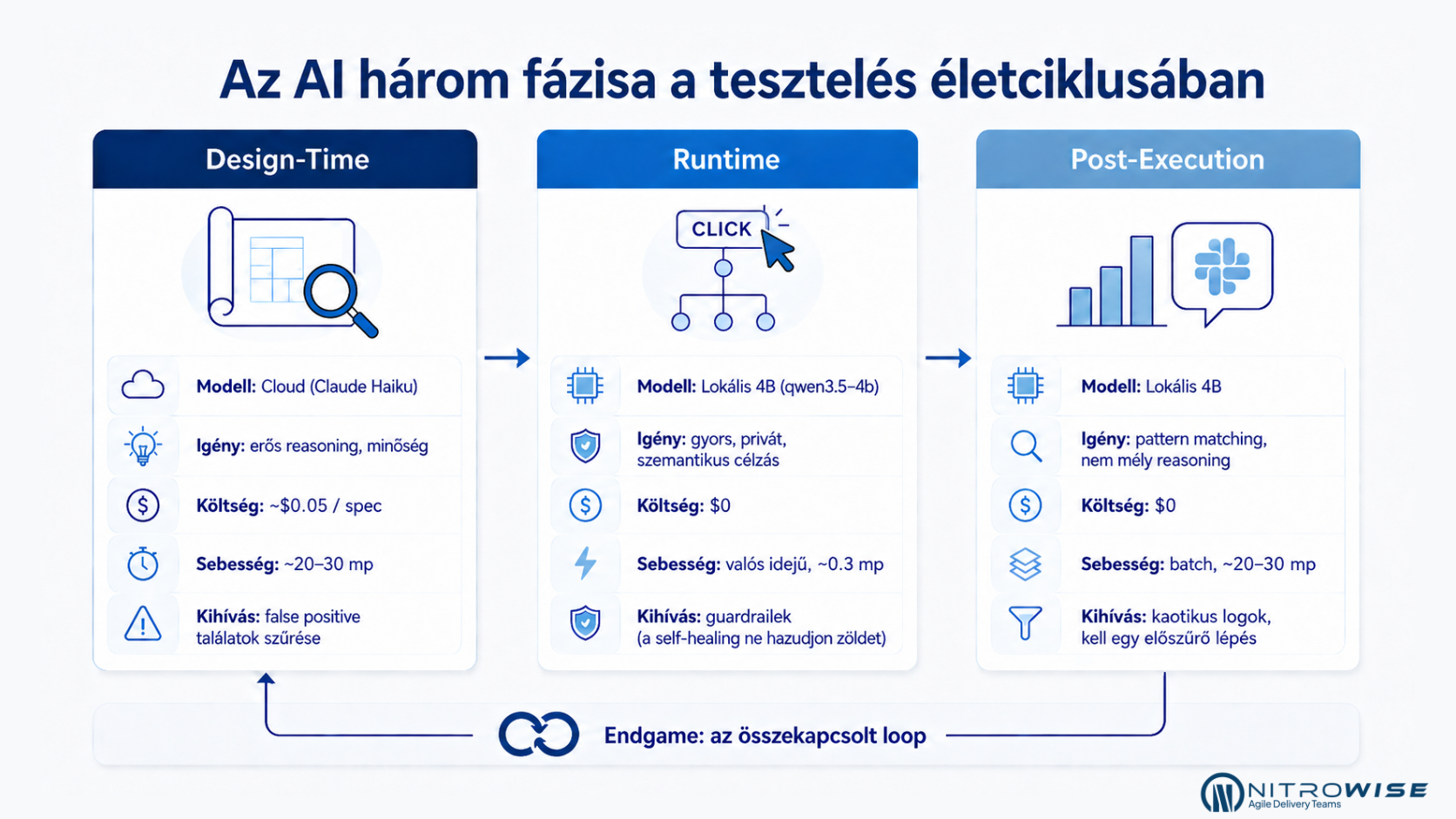
A három fázis
A tesztelésnek életciklusa van. Ezt eddig is tudtad, ha láttál már vállalati fejlesztési projektet. Megtervezed, mit kell tesztelni. Lefuttatod a teszteket. Kielemzed, mi történt. Minden tesztkörnyezet (harness), amit valaha építettél vagy vettél, ezt a három lépést követi.
Az AI mindhárom fázisba beilleszthető. De nem ugyanaz az AI: más modellek, más méret, más kompromisszumok (tradeoffok). Könnyű reflexből a legnagyobb elérhető modell után nyúlni, de pont az a legérdekesebb, hogy mennyire eltérnek a követelmények az egyes fázisokban.
Így néz ki a valóságban:
Design-Time
Még mielőtt egyetlen sor kód megszületne. Van egy specifikációd, egy JIRA ticketed, vagy a Product Owner vágyálmai. Odaadod egy modellnek, és megkérdezed: „Mi hiányzik? Mi kétértelmű? Mi fog eltörni?” A modell úgy olvassa a specifikációt, mint egy senior QA architect. Megérti, nem pedig azonnal kódot generál. Cloud alapú, publikus modell kell hozzá. Specifikációnként egyszer fut le. ~$0.05 elemzésenként.
Runtime
Fut a teszt. Az éjszakai deploy során megváltozott a kilépés gomb CSS osztálya. A $('a.button.secondary.radius') selector-od, amely egyértelműen beazonositja a gombodat a webalkalmazásodban, halott. Egy kis lokális modell újra megvizsgálja a DOM-ot (Document Object Model, lényegében a weboldalad alaprajza), szemantikus szándék alapján megtalálja a gombot („click the logout button”), és a teszt folytatódik. 300ms. $0. Teljesen privát, semmi nem hagyja el a gépedet.
Post-Execution
Lezárult az éjszakai tesztfutás. 847 teszt, 23 hiba, 14 000 sor JUnit XML. Egy embernek 30-45 percébe telik ezt átnyálazni. Ha a nyers 14 000 sort egy az egyben ráküldöd egy kis lokális modellre, elhasal rajta, hiszen túl nagy a kontextus, túl sok a zaj. Ehelyett egy script előszűrheti pusztán a stacktrace-eket és a hibát jelző blokkokat. Ez a sűrített részhalmaz megy a lokális 4B modellhez. A modell ~20 másodperc alatt feldolgozza; a teljes pipeline, a nyers XML-től a szűrt, fókuszált kimenetig nagyjából 20-30 másodperc alatt fut le. Gyökérokok alapján csoportosítja a hibákat, és osztályoz: alkalmazás hiba, teszthiba, környezeti hiba, instabil teszt. Végül megírja a Slack/Teams összefoglalót. $0. Privát.
A beszélgetések, amiket a szakmában hallok, szinte teljesen a #2-es pontra, a runtime-ra fókuszálnak. A másik kettő is megér egy misét.
Design-Time: Kapd el a bugokat, mielőtt kód létezne
Mi, emberek, kifejezetten rosszak vagyunk abban, hogy észrevegyük, ami nincs ott. Elolvasunk egy specet, bólogatunk – „igen, jelszóvisszaállítás emailben, a link 1 óráig érvényes, minimum 8 karakter” -, és késznek nyilvánítjuk. Nem áll rá az agyunk, hogy a hiányosságokat keressük.
Egy nyelvi modellé viszont igen.
Itt egy spec a demómból, elfelejtett jelszó feature. Első ránézésre rendben van:
Feature: Elfelejtett jelszó
- A felhasználó emailben kérhet jelszóvisszaállítást
- A visszaállító link 1 óráig érvényes
- Az új jelszó minimum 8 karakter
- Sikeres visszaállítás után a felhasználó a login oldalra kerülBeszórtam egy modellbe egy egyszerű prompttal: „Elemezd tesztelési teljesség szempontjából. Mi hiányzik? Mi kétértelmű?”
Talált 11 hiányzó exception scenariót és 5 kétértelmű viselkedést. A specifikációban 5 követelmény volt: a modell kiszúrta, hogy a következők soha nem lettek definiálva:
- Mi a viselkedés, ha az email nem létezik? (user enumeration kockázat)
- Jelszó újrahasználati szabályzat (újra megadhatja a régit?)
- Rate limiting a visszaállító endpointon
- Párhuzamos visszaállítási kérések (ha kér egy másodikat, az első link invalidálódik?)
- Hiba esetén mi a response formátum? (JSON? HTML redirect?)
Ezek nem elvetemült edge case-ek. Ez a különbség egy olyan feature között, ami csak happy path-en működik, és egy olyan között, ami nem szivárogtatja a felhasználói adatokat.
A kód fájdalmasan egyszerű:
const response = await anthropic.messages.create({
model: 'claude-haiku-4-5-20251001',
max_tokens: 2048,
system: `You are a senior QA architect. Analyze for testing completeness.
Return JSON: { completeness, specByExample, testCases, summary }`,
messages: [{ role: 'user', content: `Evaluate:\n\n${spec}` }]
});Költség: ~$0.05. Idő: ~2 másodperc. Érték: tervezési hibák megfogása még azelőtt, hogy egyetlen sor kód is megszületne.
Fontos kitétel
A modell potenciális hiányosságokat flagel. Nem ismeri a rendszered teljes scope-ját, a threat modeledet, és azt sem, mit hagytatok ki szándékosan. Annak a 11 megjelölt scenariónak egy része false positive lesz. Olyan dolog, amit a PO már átgondolt és elvetett. A modell feladata az, hogy ezeket a felszínre hozza; az emberé pedig az, hogy eldöntse, melyik számít.
Túl sokszor láttam már az inverzét. A fejlesztés követelményei átbeszélésre, elfogadásra kerültek. A fejlesztők lefejlesztik. A tesztelők megírják a teszteket. Három sprinttel később valaki rájön, hogy a specifikáció rossz volt. A feature egyszerűen nem illeszthető a rendszerbe úgy, ahogy a PO megálmodta. Kezdődhet az újraírás, az ujjal mutogatás, és az a bizonyos sprint hirtelen 40%-kal több carryovert fog tartalmazni.
Egy korábbi engineering managerem ennél is tovább ment. 260 létező business test case-t térképezett fel egy design rendszerbe, közvetlenül az architekturális specifikációk mellé. Amikor beesett egy új feature ticket, a modell azonnal meg tudta mondani: hol metszi az új logika a meglévő teszteket, milyen tesztelési szinteken (unit, API, UI) kell lefedni, és milyen konkrét példák bizonyítják majd, hogy a feature működik. Senkinek nem kellett 15 percig magyaráznia a rendszert egy új belépőnek. A modell már mindent elolvasott.
Modell választás design-time-ra
Cloud. A reasoning (következtetés) minősége számít, és ezt specifikációnként egyszer futtatod, nem tesztfutásonként. Claude Haiku vagy valami hasonló. Olcsó, gyors, és untig elég.
Runtime: Intent alapján tesztelj, ne az alkalmazásod gombjai alapján
A runtime az a fázis, amiről a legtöbb szó esik. A nyilvánvaló felhasználás: „Az AI tud gombokat kattintani → használjuk az AI-t gombok kattintására.” Tiszta sor. Az ez alatt megbúvó architektúra viszont sokkal többet nyom a latban, mint elsőre gondoltam.
A pattern, ami ténylegesen működik: observe → reason → act → evaluate (megfigyel → értelmez → cselekszik → kiértékel), egy lokális modellen futtatva:
1. OBSERVE — DOM snapshot, interaktálható elemekre szűrve (a DOM ~80%-a kuka)
2. REASON — "Melyik elem felel meg a 'login button'-nek?" → lokális 4B modell
3. ACT — Végrehajtás standard WebdriverIO parancsokkal
4. EVALUATE — Sikeres volt? Ha nem, etesd vissza a hibát → REASON újraÍgy néz ki ez a tesztben:
// Tradicionális: stabil elemek, amiket kontrollálsz
await $('#username').setValue('tomsmith');
await $('#password').setValue('SuperSecretPassword!');
// Agentic: flaky vagy kiszámíthatatlan elemek
await browser.agent('click the button that submits the login form');
// Tradicionális: ellenőrizd az eredményt
await expect($('.flash.success'))
.toHaveText(expect.stringContaining('You logged into a secure area!'));Az agent hívás egy strukturált akció-listával tér vissza – a modell sosem nyúl közvetlenül a böngészőhöz:
[
{ "type": "CLICK", "target": { "css": "button[type='submit']" } }
]Ez a hibrid megközelítés. Tradicionális megoldás arra, ami stabil. Agentic arra, ami változik. Mindezt ugyanabban a tesztben, hibrid módon, mindegyiknek a saját erősségét kihasználva.
Self-healing: Amikor a selektorok meghalnak
A legértékesebb és leggyorsabban megtérülő funkció a self-healing. A logout gomb CSS osztálya megváltozott a legutóbbi deployban: .button.secondary.radius helyett .button.alert.radius lett. A tradicionális selektorod halott. A teszt elszáll.
Agentic targeting használatával semmi sem változik. A prompt továbbra is browser.agent('click the logout button'). A modell újra megfigyeli a DOM-ot, szemantikai szerepe és szövege alapján megtalálja a gombot, és az új selektorra kattint. Nulla tesztkód módosítás.
Az agent ~300ms-ot ad a futáshoz. Egy elhasalt teszt + újra futtatás + manuális debugolás = 10+ perc.
Egy elrettentő példa
Láttam én már self-healinget nagyon csúnyán félremenni. Egy Playwright setup úgy lett konfigurálva, hogy futásidőben „javítsa” a törött selector-okat. Amikor egy kívánságlista feature elkezdett elszállni, az SDK hibásan lett bekötve, a kattintásokat a rendszer nem regisztrálta, és az AI azzal „javította” meg a helyzetet úgy, hogy natív JavaScriptet injektált a böngészőbe. A teszt kizöldült. 30 percen át futott, végig zölden. Az alkalmazás viszont továbbra is rossz volt. A modell arra optimalizált, hogy zöld legyen a teszt, nem arra, hogy validálja a rendszert.
A guardrailek kellenek. Az agent akcióit szigorúan az elemek megkeresésére (element targeting) és az értékek beállítására (value setting) kell korlátozni. Ha a self-healing keretrendszered tetszőleges szkriptet tud injektálni a futásba, akkor az nem self-healing, csak egy teszt, ami hazudik neked.
De még ezekkel a korlátokkal sem fekete mágia a szemantikus célzás. Ha egy deploy során a submit gomb teljesen eltűnik a DOM-ból, egy 4B modell, ami megkapja a választható DOM elemek listáját, simán visszaadhatja az „Add User” gomb selektorát is, elvégre ez a legközelebbi szemantikus találat. A különbség a fenti Playwright-sztorihoz képest az, ami ezután történik: az agent végrehajtja a kattintást, de az ezt követő tradicionális assertion – expect($('.flash.success')).toHaveText(...) – elszáll, mivel az „Add User” gombra kattintva nem kapsz login success üzenetet. A teszt gyorsan és egyértelmű hibával hasal el ahelyett, hogy 30 percig csendben hazudná a zöldet. A hibrid minta a biztonsági hálód: az agent kezeli a „keresd meg ezt az elemet” problémát, de a teszt kimenetét továbbra is determinisztikusan ellenőrzöd.
Modell választás runtime-ra
Lokális 4B (én qwen3.5-4b-t használok LM Studión keresztül). ~300ms latency. $0 hívásonként. Teljesen privát, semmi nem érint külső cloud API-t. Az esetek 80%-ában, amikor az element targeting egyértelmű, ennyi bőven elég. A maradék 20%-ra (iszonyat komplex oldalak, kétértelmű labelek) skálázódhatsz felfelé egy 7-14B lokális modellre, vagy egy gyors cloud modellre. De ne a cloud legyen az alapértelmezett. A free legyen az.
Post-Execution: Riportok, amelyek osztályozzák önmagukat
Ezt a fázist hagyják figyelmen kívül a legtöbben, pedig itt adja a legnagyobb időmegtakarítást (time-to-value) egy aprócska modell.
A forgatókönyv: lefutott az éjszakai teszt. 847 teszt, 23 hiba. A JUnit XML kimenet: 14 000 sor. Egy QA mérnök minden áldott reggel 30-40 percig görgeti a Jenkinst, és ugyanazokra a kérdésekre keresi a választ: Ez egy igazi bug? Instabil a teszt? Elszállt a környezet? Vagy maga a teszt a rossz?
Itt van, mi történik, ha ugyanezt a riportot átzavarod egy lokális 4B modellen:
const prompt = `Classify these failures into APP_BUG, TEST_BUG, ENV, or FLAKY.
Group related failures by root cause. Write a 3-sentence Slack summary.
Suggest concrete actions.`;
const analysis = await fetch('http://localhost:1234/v1/chat/completions', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ model: 'qwen/qwen3.5-4b', messages: [{ role: 'user', content: prompt }] })
});A modell egy strukturált JSON-t ad vissza:
{
"groups": [
{ "rootCause": "/api/products returning 500 since 3am deploy",
"category": "APP_BUG", "count": 18 },
{ "rootCause": "Checkout UI átszabva — selektorok változtak",
"category": "TEST_BUG", "count": 3 },
{ "rootCause": "Teszt credential-ök lejártak",
"category": "ENV", "count": 2 }
],
"summary": "23-ból 18 hiba az /api/products 500-as válasza miatt van a hajnali 3-as deploy óta. 3 hiba selektor változás a checkoutban. 2 lejárt credential. Rollback javasolt.",
"actions": [
{ "action": "FILE_BUG", "priority": "critical",
"title": "/api/products returning 500 since 3am deploy" }
]
}23 hiba → 3 root cause. A végső döntést továbbra is egy ember hozza meg, de úgy ül le a gép elé, hogy az elemzés oroszlánrésze már kész van. A 30-40 perces feladatból 2 perc lett.
Ez strukturált kimenettel működik a legjobban: JUnit XML, Mocha JSON, vagy bármi, aminek világos határai vannak. A valódi tesztlogok ennél sokkal mocskosabbak: levágott stack trace-ek, csendes timeoutok hibaüzenet nélkül, vagy egy OOM kill, ami semmit nem hagy maga után. Ezekkel egy 4B modell is meg fog szenvedni. Minél kaotikusabb a logod, annál kritikusabb lesz a pre-filter lépés.
Egy korábbi munkahelyemen a backend fejlesztők éjszakánként tízszer futtattak le 2000 API tesztet. Az volt az elmélet, hogy a puszta ismétlésszám felszínre hozza a flakyness-t. Felszínre is hozta, cserébe belefojtotta a QA csapatot a zajba. Minden reggel ugyanúgy indult: Jenkins pörgetés, ellenőrizni, hogy az 500-asok valódi hibák-e vagy csak tranziensek, majd összevetni őket a következő retry eredményével. Építettünk egy CLI tool-t, ami ráküldte a riportot egy kis lokális modellre. A modell csoportosította a hibákat, detektálta a retry-ok közti mintázatokat, és megjelölte azokat, amikkel tényleg érdemes volt foglalkozni. A reggeli triázsra szánt idő kb. 80%-át megspóroltuk vele.
Az adatvédelem itt kritikus. A riport soha nem hagyja el a gépedet. Nincs API kulcs, nincs cloud vendor, semmilyen adat nem jut ki a belső hálózatodból. Egy erősen szabályozott iparágban dolgozó cégnél ez jelenti a különbséget aközött, hogy „ezt bevezethetjük” és aközött, hogy „a jogi osztály rögtön megvétózta”.
Modell választás post-execution-re
Lokális 4B. A klasszifikáció pattern matchinget (mintafelismerést) igényel, nem komoly reasoninget. Nem kell 200 milliárd paraméteres modell ahhoz, hogy a gép észrevegye: 18 hiba pontosan ugyanazt az API endpointot érinti és másodpercre pontosan ugyanakkor kezdődtek. És egy filléredbe sem kéne, hogy kerüljön.
A modell stratégia: A megfelelő eszközt a megfelelő feladathoz
A minta, ami nálam abszolút bevált: egy 4B modell meglepően sok mindent megold ingyen. Próbálok nem méregdrága frontier tokeneket elégetni olyan dolgokra, amit egy kis lokális modell 300ms alatt megold.
| Szint | Méret | Hol fut | Mire jó | Fázis |
|---|---|---|---|---|
| Micro/Small | 1-4B | Lokális, ingyen | Elem kattintások, riport triázs | Runtime, Post-exec |
| Medium | 7-14B | Lokális, ingyen | Specifikáció kiértékelés, pattern detekció | Design-time, Post-exec |
| Fast Cloud | pl. Flash, Mini | API, olcsó | Teszt design, intent következtetés | Design-time |
| Frontier | pl. Pro, Opus | API, drága | Stratégia, autonóm exploráció | Endgame |
Ökölszabály
kicsi és lokális modell a gyakori feladatokra. Nagy és felhős a ritka, de komoly reasoninget igénylő feladatokra. Egy lokális 4B az element targeting 80%-át csuklóból megoldja. Egy lokális 7B teljesen kompetens specifikáció-kiértékelést tud végezni. A frontier modellek megmaradnak az endgame-re, (az összekapcsolt, autonóm loop-ra) de ezt nem jövő héten kéne elkezdened építeni.
A rosszul megválasztott modellméretnek komoly ára van. Pár történet, ami szembejött velem a piacon:
- Egyetlen JIRA ticket, amit egy kontrollálatlan agentic workflow-n küldtek át: $200
- Egy mobilfejlesztő költsége 2-3 hónapnyi agentic kódolás után: $4,000
- Egy agentic fejlesztési kísérlet, amit véletlenül hagytak pörögni: $35,000 egyetlen hónap alatt
- Fejlesztőcsapatok, akik a teljes havi token-keretüket elégették kevesebb mint 48 óra alatt
A token gazdaságtan nem túl bonyolult. A drága modellek ritka, nehéz reasoning feladatokra valók. Az ingyenes, lokális modellek pedig minden másra.
Egy fontos megjegyzés az „ingyenes” szóhoz: a lokális modelleknek mérnöki óradíjban mérhető ára van. Valakinek fel kell telepítenie az LM Studiót vagy az Ollamát, naprakészen kell tartania, debugolni kell, ha egy modellfrissítés eltöri a pipeline-t, és biztosítani kell, hogy minden fejlesztői gépen legyen elég RAM a futtatáshoz. Egy szóló fejlesztőnek vagy egy olyan csapatnak, ahol már bejáratott a lokális tooling, ez triviális. De egy olyan csapat számára, amelyik életében nem nyúlt még lokális inference-hez, havi $1 elköltése egy cloud API hívásra olcsóbb megoldás lehet, mint a lokális üzemeltetés (overhead). Ott kezdd, ahol a legkevesebb a súrlódás a jelenlegi rendszeredben.
Az Endgame: Az összekapcsolt loop
Ma ez a három fázis csak lazán kapcsolódik egymáshoz. Minden átadást egy ember vezérel: elolvassa a specet, megírja a tesztet, majd átnézi a riportot.
Az endgame az lesz, amikor ezek egyetlen folyamatos loop-pá olvadnak össze:
Specifikáció változás → Teljesség ellenőrzés → Teszt skeleton generálás
→ Végrehajtás self-healinggel → Eredmények triázsolása → Auto-PR fixek → Spec frissítéseA fenti elemek egytől egyig léteznek ma: a demók, amiket megmutattam, nem pusztán elméletiek. A nehéz rész az integráció. A kontextus átadása fázisok között úgy, hogy az ne degradálódjon. Tudni, hogy mikor kell egy problémát egy ember felé eszkalálni. És a legfontosabb: elég transzparenssé (observable) tenni a loop-ot ahhoz, hogy tényleg megbízz benne. Mert a valódi rémálom ez: az agent hibázik egyet, nyit rá egy PR-t, az bemergelődik, eltöri a CI-t, és onnantól a loop elkezdi mérgezni önmagát. A bizalmi létra 4. szintje nem csak a modell minőségéről szól; arról is, hogy felépíted azt az observability hálót, ami még a láncreakció beindulása előtt megfogja a hibát.
Ez a bizalom nem fog azonnal kialakulni. Lépésről lépésre mászol felfelé:
- Shadow: Az agent párhuzamosan fut a meglévő tesztekkel. Az eredményeket csak összehasonlítjuk, nem blokkol. (1. hónap)
- Advisory: Az agent találatai emberi felülvizsgálatra (review) mennek. (2-3. hónap)
- Gated: Az agent automatikusan lekezeli az ismert flow-kat, az ismeretleneket viszont eszkalálja. (3-6. hónap)
- Autonomous: Az agent önállóan fut, döntéseket hoz, riportol, és saját maga nyitja a PR-okat. (6+ hónap)
Az autonóm tesztelést nem lehet csak úgy élesíteni (deployolni). Bele kell nőni.
Ha felkeltette az érdeklődésedet
Nem azt állítom, hogy ez az egyetlen üdvözítő út, vagy hogy mindent így kell csinálni. Egyszerűen csak ezekkel kísérletezgettem az elmúlt időszakban. De ha te is kedvet kaptál hozzá, nagyjából ezt a sorrendet javaslom a kezdéshez:
A Design-time a legegyszerűbb belépési pont. Fogj egy specifikációt vagy egy JIRA ticketet, másold be egy LLM-be, és kérdezd meg, mi hiányzik belőle. Semmi script írás, semmi setup, kerek öt perc az egész. Amikor először csináltam ezt, őszintén megdöbbentem, mi jött vissza.
A Runtime fázissal töltöttem el a legtöbb időt. A wdio-agent-service az a cucc, amit pont erre a célra építettem: bedobsz egy browser.agent('click the logout button') sort egy teljesen hagyományos WebdriverIO tesztbe, és az szépen lefut egy lokális modellen. Maga a self-healing rengetegszer mentett már meg attól, hogy sokperces checkout flow-kat kelljen újra lefuttatnom csak azért, mert egy frontend fejlesztő átírt egy CSS osztályt.
A Post-execution volt a legnagyobb meglepetés számomra. Nem vártam sokat attól, hogy egy JUnit riportot átzavarok egy apró 4B modellen, de a minden reggel 30 percet felemésztő triázsból végül egyetlen, azonnal használható Slack üzenet lett. Az adatvédelem (hogy egyetlen bájt sem hagyja el a gépet) pedig sokkal többet nyomott a latban, mint ahogy először gondoltam. Főleg, miután beszéltem pár sráccal olyan cégektől, ahol a tesztadatok értelemszerűen nem érintkezhetnek külső API-kkal.
Én egyelőre biztosan nem próbálnám mind a hármat összegyúrni valami elszabadult autonóm loop-pá. A darabkák már léteznek, de az integráció még várat magára. Viszont a fázisok önmagukban, külön-külön használva? Meglepően hasznosak.
Happy testing!

