Egyre több cég kísérletezik AI-alapú dokumentum-feldolgozással: valaki bedob pl egy szkannelt, vagy pdf-ben érkező dokumentumot (Mérleg, főkönyv, bejövő számláját) egy chatbotba az kinyeri az adatokat, és máris úgy érzi, megoldotta a problémát. Ez az élmény valós – de csak az út eleje.
A dokumentum-felismerés és adatkinyerés területén legalább hat jól elkülöníthető megoldási szint létezik. A különbség nem csupán technikai: minden szint más üzleti kockázatot, más üzemeltetési igényt és más integrációs mélységet jelent. Egy egyedi szoftverfejlesztő cégnek, amely már 20-30 hasonló megoldást valósított meg, pontosan tudnia kell – és el kell tudnia magyarázni –, hogy mi az a tudás, amit a chatbot-kísérlet után kell elvégezni ahhoz, hogy az eredmény valóban beilleszthető legyen egy vállalati folyamatba.
Ez a cikk azt mutatja be, hogy mi a különbség az egyes szintek között, és mit ad hozzá minden egyes lépés az előzőhöz képest. A cél nem a technológia bemutatása önmagában – hanem annak megértése, hogy mikor van szükség tapasztalt AI-fejlesztő partnerre, és miért nem elegendő egy gyors prototípus.
A kép tartalma szövegesen
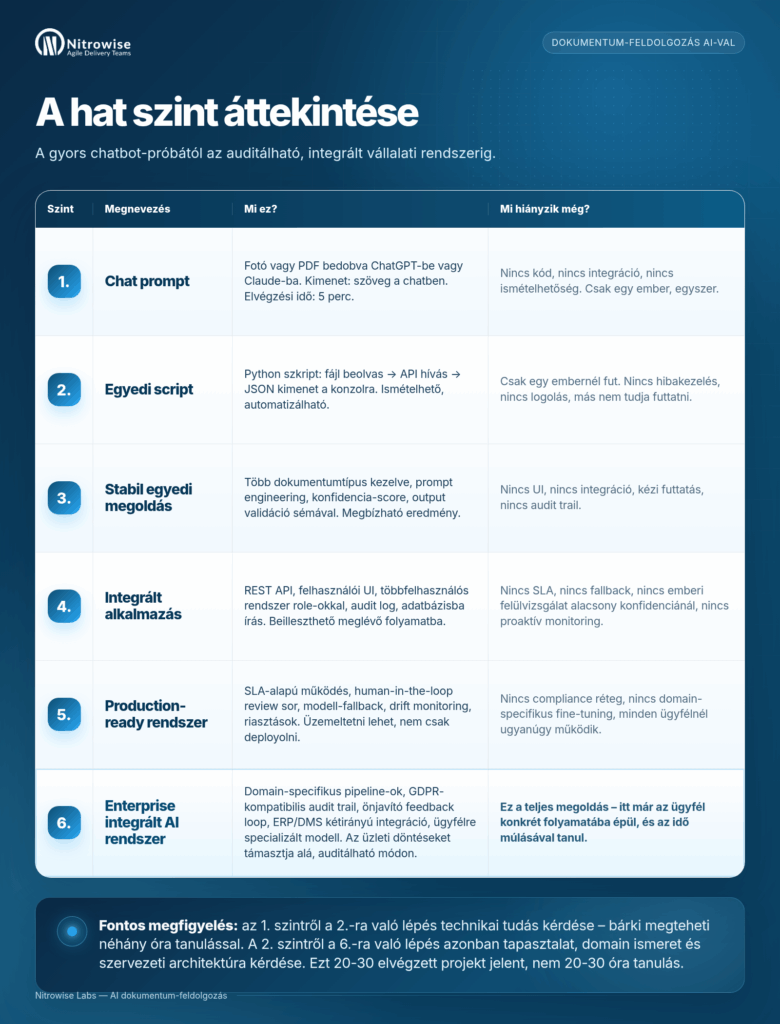
A hat szint áttekintése
| Szint | Megnevezés | Mi ez? | Mi hiányzik még? |
|---|---|---|---|
| 1. | Chat prompt | Fotó vagy PDF bedobva ChatGPT-be vagy Claude-ba. Kimenet: szöveg a chatben. Elvégzési idő: 5 perc. | Nincs kód, nincs integráció, nincs ismételhetőség. Csak egy ember, egyszer. |
| 2. | Egyedi script | Python szkript: fájl beolvas → API hívás → JSON kimenet a konzolra. Ismételhető, automatizálható. | Csak egy embernél fut. Nincs hibakezelés, nincs logolás, más nem tudja futtatni. |
| 3. | Stabil egyedi megoldás | Több dokumentumtípus kezelve, prompt engineering, konfidencia-score, output validáció sémával. Megbízható eredmény. | Nincs UI, nincs integráció, kézi futtatás, nincs audit trail. |
| 4. | Integrált alkalmazás | REST API, felhasználói UI, többfelhasználós rendszer role-okkal, audit log, adatbázisba írás. Beilleszthető meglévő folyamatba. | Nincs SLA, nincs fallback, nincs emberi felülvizsgálat alacsony konfidenciánál, nincs proaktív monitoring. |
| 5. | Production-ready rendszer | SLA-alapú működés, human-in-the-loop review sor, modell-fallback, drift monitoring, riasztások. Üzemeltetni lehet, nem csak deployolni. | Nincs compliance réteg, nincs domain-specifikus fine-tuning, minden ügyfélnél ugyanúgy működik. |
| 6. | Enterprise integrált AI rendszer | Domain-specifikus pipeline-ok, GDPR-kompatibilis audit trail, önjavító feedback loop, ERP/DMS kétirányú integráció, ügyfélre specializált modell. Az üzleti döntéseket támasztja alá, auditálható módon. | Ez a teljes megoldás – itt már az ügyfél konkrét folyamatába épül, és az idő múlásával tanul. |
Fontos megfigyelés: az 1. szintről a 2.-ra való lépés technikai tudás kérdése – bárki megteheti néhány óra tanulással. A 2. szintről a 6.-ra való lépés azonban tapasztalat, domain ismeret és szervezeti architektúra kérdése. Ezt 20-30 elvégzett projekt jelent, nem 20-30 óra tanulás.
A 6. szint részletesen: enterprise integrált AI dokumentum-feldolgozás
Az első szintekről rengeteg szó esik a különböző platformokon, így mi most csak az utolsóra koncentrálunk. A 6. szint lényege, hogy a rendszer nem önmagában áll; beépül az ügyfél üzleti folyamataiba, és az idő múlásával tanul és javul. Négy nagy pillérre épül.
1. pillér: domain-specifikus feldolgozás
Az alacsonyabb szinteken mindenki ugyanazzal a prompttal próbál minden dokumentumot feldolgozni. A 6. szintű rendszerben minden dokumentumtípusnak saját pipeline-ja van.
Egy autó törzskönyv, egy import forgalmi engedély és egy lízingszerződés nem ugyanaz a prompt. Az eltérő mezőstruktúrák, rövidítések, eltérő minőségű szkennelések mind más kezelést igényelnek. A pipeline elemei dokumentumtípusonként:
- Saját pre-processing lépés: képminőség-ellenőrzés, forgatás-korrekció, OCR-profil kiválasztása az adott típushoz.
- Saját prompt-sablon: az adott dokumentumtípus mezőit, rövidítéseit, tipikus hibáit ismerő prompt, nem egy generikus „adj ki JSON-t” utasítás.
- Saját validációs szabályok: törzskönyvnél alvázszám checksum és rendszám regex + adatbázis-keresztellenőrzés; számlánál ÁFA-összeg cross-check és kötelező mezők; szerződésnél aláírók azonosítása és hatályossági logika.
Ezt a tudást csak akkor lehet felépíteni, ha valaki már látott öt variánst ugyanabból a dokumentumtípusból, és tudja, hol szoktak az eltérések lenni.

2. pillér: human-in-the-loop és konfidencia-menedzsment
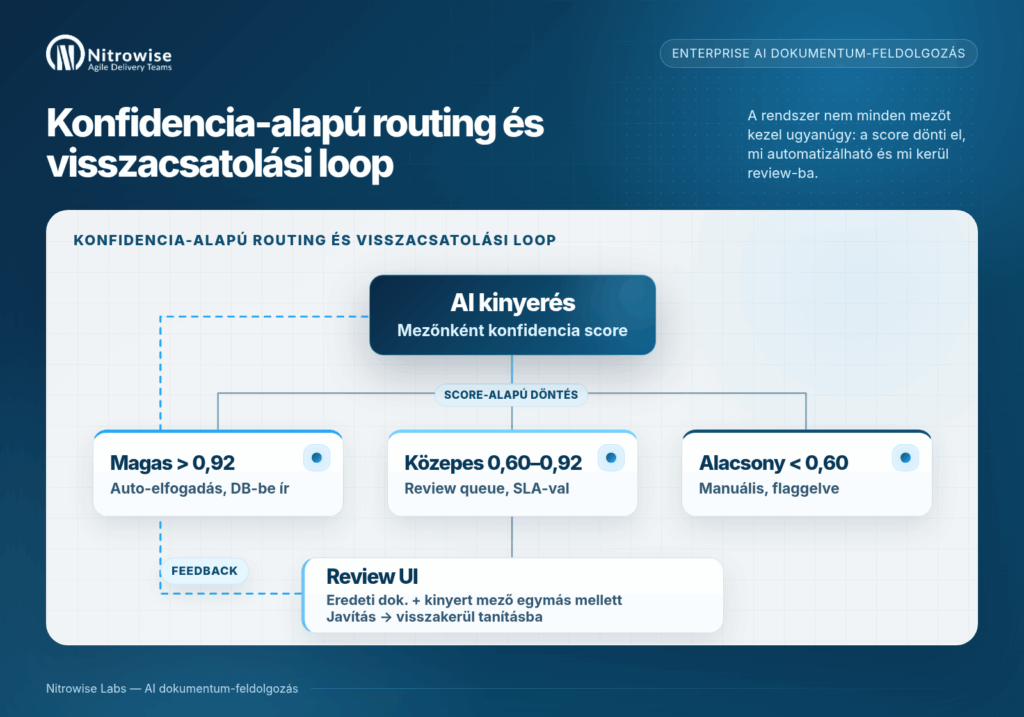
Az egyszerű megoldások binárisak: vagy működik, vagy nem. A 6. szintű rendszer mezőnként tud konfidencia-score-t adni, és pontosan tudja, mikor kell emberi döntés.
A kép tartalma szövegesen
A három konfidencia-sáv és az azokhoz tartozó routing:
- Magas konfidencia (pl. >0,92): auto-elfogadás, közvetlen adatbázisba írás, emberi beavatkozás nélkül.
- Közepes konfidencia (0,60–0,92): emberi review sorba kerül, SLA-val (pl. 4 órán belül valakinek jóvá kell hagynia). A felhasználó az eredeti dokumentumot és a kinyert mezőt egymás mellett látja.
- Alacsony konfidencia (<0,60): manuális feldolgozásba kerül, jelöléssel, hogy miért nem boldogult a rendszer.
A review UI nem utólagos gondolat, hanem az architektúra szerves része. Ami ennél is fontosabb: a felhasználó által végrehajtott javítások visszakerülnek a tanítási adatbázisba – ez alapozza meg a 4. pillér önjavító mechanizmusát.
3. pillér: compliance és audit trail
Ez az elem, amelyet a legtöbb ügyfél csak az első belső ellenőrzésnél vagy adatvédelmi auditnál értékel meg igazán.

A kép tartalma szövegesen
Minden egyes feldolgozási eseményhez rögzített rekord tartozik:
- Feltöltésnél: timestamp, felhasználó ID, forrásrendszer.
- AI kinyerésnél: modell verzió, mezőnkénti konfidencia-score-ok.
- Review kérésnél: SLA indulása, prioritás.
- Emberi jóváhagyásnál: ki, mikor, mit változtatott az eredeti AI-outputhoz képest.
- Adatbázisba írásnál: melyik táblába, melyik rekordba, milyen értékkel.
- Törlésnél/archiválásnál: jogi alap, adatmegőrzési szabály.
Az audit trail felhasználása: GDPR-audit során visszakereshetőség, modell drift jelzése (ha a pontosság csökkenni kezd), SLA teljesítmény mérése, hibavizsgálat, és – a 4. pillér szempontjából – a tanítási adatok forrása.
4. pillér: önjavító feedback loop
Fontos tisztázni: a „folyamatos fine-tuning” kifejezés megtévesztő. A valóságban ez ciklikus, és három különböző sebességű rétegből áll:
- Prompt és szabályfrissítés (naponta): ha a human review kiderít egy mintát – például hogy a cég mindig „B.sz.” rövidítéssel írja a bizonylatsorszámot –, ez azonnal bekerül a prompt-sablonba vagy a rule engine-be. Nulla gépi tanulás, azonnal élesedik.
- RAG adatbázis bővítés (hetente–kéthetente): a javított dokumentum-mező párok (eredeti szöveg → helyes érték) bekerülnek egy vektoros keresőbe. Amikor új dokumentum érkezik, a rendszer megkeresi a leghasonlóbb korábbi példákat, és azokat kontextusként illeszti be a promptba. Ez az ügyfél-specifikus memória.
- Tényleges fine-tuning (havonta–negyedévente): csak akkor szükséges, ha a dokumentumtípus annyira eltér az alap modell tudásától, hogy a prompt és a RAG nem elég. Ilyenkor összegyűjtenek néhány ezer javított példát, és egy kisebb, dedikált extraction modellt újratanítanak – nem a teljes LLM-et.

Az egész mechanizmust egy drift monitoring rendszer fogja össze. Ha az auto-elfogadási arány csökkenni kezd, vagy a review arány nő, a rendszer jelzi, hogy valamelyik rétegben frissítés szükséges – mielőtt üzleti kár keletkezik.
Ennek az egésznek van egy stratégiai következménye is: a rendszer az adott ügyfél dokumentumain tanult. Ha egy biztosítónál 6 hónapig fut, és 50 ezer kárbecslést dolgozott fel, a modell ismeri a cég sablonját, a kezelők elírási szokásait, az ügyfélkör specifikus fordulatait. Ez a felhalmozott tudás nem másolható és nem vehető el – ez az a versenyhátrány, amellyel egy belső, gyorsan összerakott megoldás soha nem tud felzárkózni.
Összefoglalás
A dokumentum-feldolgozás területén az AI valóban működik – de a „működik” szó nagyon különböző dolgokat takarhat az 1. és a 6. szint között. A chat-alapú prototípus megmutatja, hogy lehetséges. Az enterprise szintű rendszer megmutatja, hogy megbízható, auditálható, integrálható és az idő múlásával egyre jobb.
A kettő között nem egyetlen nagy lépés van, hanem hat fokozatos szint – és minden szintnél pontosan meghatározható, mi az, ami hiányzik, és miért számít az üzleti folyamat szempontjából.
Az a cég, amely már végigjárta ezt az utat 20-30 ügyféllel, nem csupán szoftvert hoz – hanem azt a tudást is hozza, hogy melyik dokumentumtípusnál mi a jellemző buktató, hogyan kell a konfidencia-küszöböt kalibrálni, és hogyan épül fel az a review folyamat, amelyet az ügyfél valóban használni fog.